
How I got into technology

Whether I'm making new friends and industry relationships, or even just participating in casual conversation, I often get asked how someone with my educational background ended up in the technology sector.
The simple answer is equal parts passion and procrastination with a sprinkling of subversion and a pinch of counter-culture.
The longer answer is that it all began when I got my first computer.
The background
Growing up while the internet was becoming prevalent was an interesting time. The graph below shows that the '90s and '00s were when internet use took off in a huge way, and my experience was no different. Learning to type on MSN Messenger, picking my online pseudonym, and being taught (incorrectly) how a search engine worked were all things I distinctly remember doing.
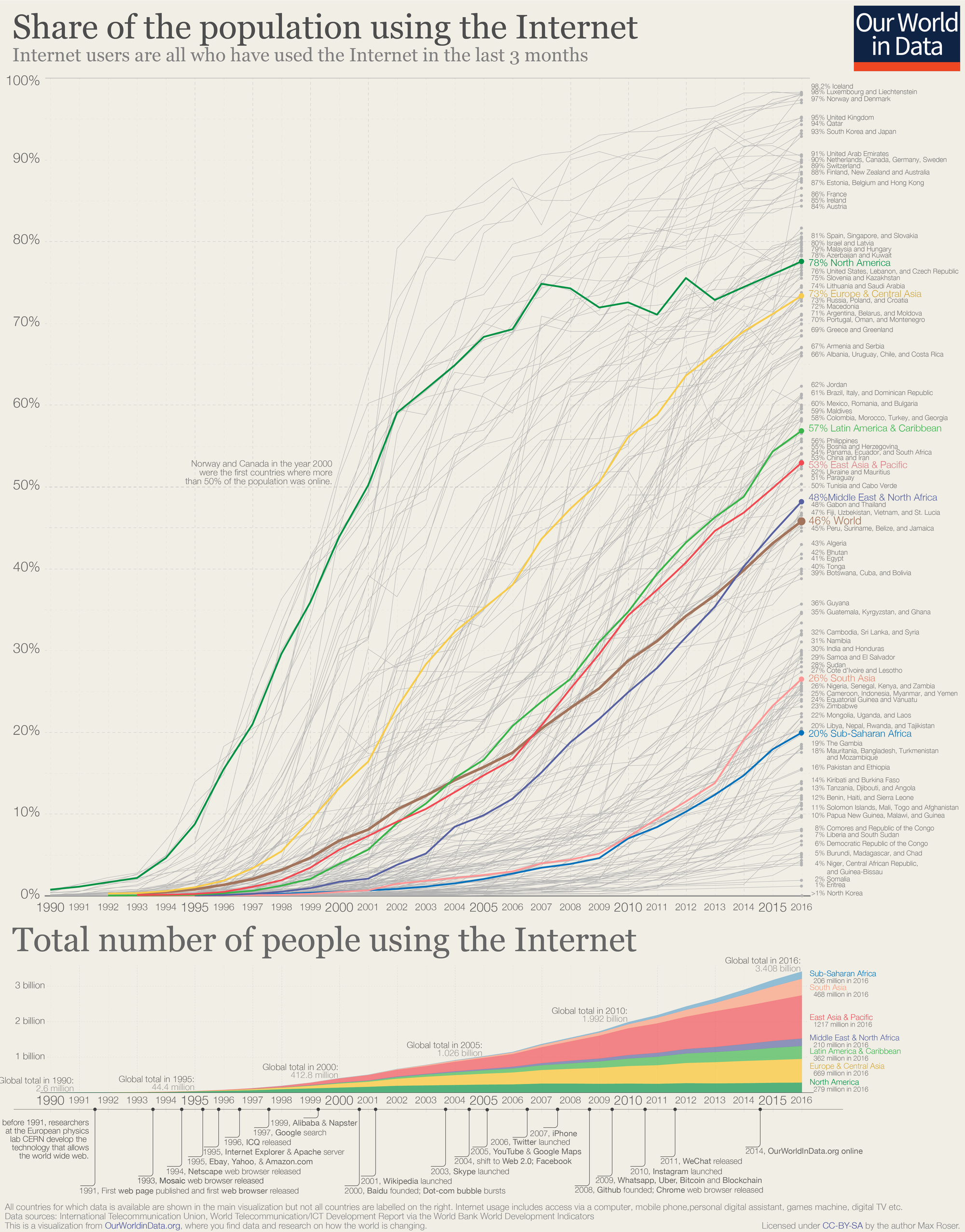
Never before or again will a generation go through formative years at the same time as both the world was becoming more connected and information was becoming more available to everyone. While a lot different now, I think the internet was much more like the Wild West as it was burgeoning. Security wasn't really much of a thing, many small sites and blogs existed in place of larger conglomerate presence, and it felt new and exciting to be a part of something that hadn't yet fully gained widespread adoption.
That all being said, I never saw much allure in studying I.T. at school, preferring rather to experiment on my own at home on my laptop. This meant idling in IRC, trying out code snippets or programs I found online without much care for the consequences, and trying to work out how to download music for free. A memory I have from the time is that I couldn't for the life of me get torrent files to download. Not knowing that a torrent client was needed, I downloaded 1kb files and furrowed my brow when they didn't play in VLC or iTunes.
I think my interest in technology was further enhanced by spending infrequent weekends with my Uncle, when he was back from university. We built computers, created LANs to play video games, and constructed elaborate train tracks around his parent's living room (more time was spent using the track eraser to get a fully conductive system than actually driving the trains). I learned how to crack games, what Warez meant, and of course finally learned how torrent files worked.
The set-up
Fast forward to university and I was happily studying chemistry, a passion I'd picked up from school and increased by my own extra-curricular home experiments. In my third year, I studied abroad, and thus began the chain of events that switched my passions from science to technology.
Living on campus in residential halls at university, everyone tussled with access to the internet and to media by the metered connection (100MB a day) hard-wired into all rooms, and the exorbitant price of data on cell-phone plans.
What we did have however was gigabit ethernet between all endpoints on the campus network backed by a connection to AARNET.
Being resourceful university students, someone had set up a Direct Connect server and students could access their share of Linux ISOs locally whilst socialising with other students over the intranet. I eventually found my way onto this server and with that started to become a part of the online university community.
Fast-forward a couple of months and I realised I'd found a friend-group in the most unlikely place. While my parents and teachers had advised me against making friends with people online, I'd instead found a group of kindred spirits – people without lots of deep technical knowledge, but with nous and determination.
I started to hang out (in-person this time) with the motley group who administrated and moderated this hub, eventually being invited to the moderator group myself and donning the stole of responsibility that came with it (mainly being heavy handed with the kick button).
I learned that what I had assumed was a deeply technical set of infrastructure, software, and glue code was actually just YnHub.exe running on an old Windows laptop in someone's dorm cupboard. As nothing was encrypted and all traffic was likely logged extensively, the laptop was moved incongruously between dorms when someone in the university IT department (we'll hear more about these later) blocked an IP.
The Challenge
Eventually, we either ran out of trusted dorm rooms to host the server, or a port was blocked that allowed DC++ to run seamlessly and all was thought lost. Everyone was sent back to their 100MB data caps and with it came a dearth of sharing large files on campus.
With that came the challenge so neatly and succinctly summarised by the following tweet. Out of the window went university work and through that same window came a lot of learning about technology.
"The best programs are the ones written when the programmer is supposed to be working on something else." - Melinda Varian
— Programming Wisdom (@CodeWisdom) September 25, 2020
We eventually came to the conclusion that the next evolution of DC++ would need to be off campus; in a place outside the reach of university IT, yet accessible to those on campus wanting to connect. One of the moderator team provided us with the root password to one of their friend's CentOS servers, and after extensive googling about how to get in to the server, we managed to open up an SSH connection. Further extensive googling provided us with a test command that we executed before shutting the window lest we broke anything.
Without the comfort zone of a GUI and with limited/no Linux knowledge, we realised that this would be significant challenge for us. Over the next few days, we followed a set of instructions to install OpenDCHub on the server and another set of instructions to open the right port in the firewall. We learned that DNS was the phone book of the internet and registered a new domain so users wouldn't have to remember our IP address and started spreading the word that we were back in business.
We'd correctly, albeit accidentally, surmised that even though DC++ used a centralised architecture, the point-to-point connections were direct. This meant no round trips from client to server for data transfer, and users were still able to benefit from the ultra-fast campus intranet.
Education by procrastination
Rather than be satisfied with the default server settings, we started a quest to be secure, performant, and user-friendly, by spending many late nights learning all there was to know about Linux so we could effectively administrate this server.
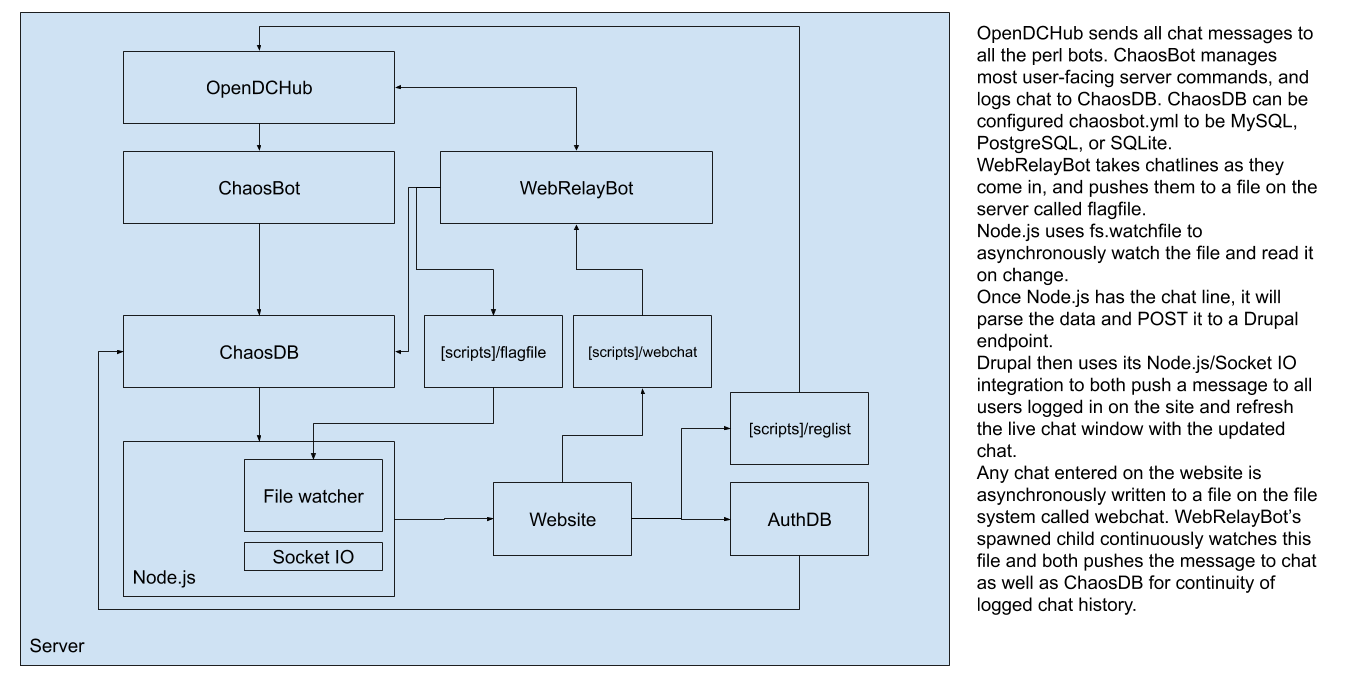
We also became aware that there was functionality baked into OpenDCHub to run bots written in Perl. We had two example bots that came with the source code, some documentation, and a smattering of examples from around the web – although nothing that we could use directly. This of course meant that our next challenge was to learn Perl and write our own. You'd better believe we sent the relevant XKCD around when things we working, as well as the other relevant XKCD when things weren't.
Running through three iterations, our Perl took the form of ChaosBot. The bot managed users, alert messages, chat statistics, chat history, and a host of other functions; including the ability to self-update. In doing this work, I learned more about the benefits of open source and how it aligned to my personal views. So much so that I published the code on GitHub to collaborate.
After we'd built our ideal bot – one that made up for all the drawbacks of our decision to use OpenDCHub – we decided to expand to the web. Knowing nothing about HTML, our first iteration was a series of flat files hosting text and poorly written CSS. I had no idea that content management systems (CMS) existed so each page was written copied from an existing page and edited in Vim.
I was informed by a friend that there was an easier way, and started to learn his recommended CMS, Drupal, to build a new site. Over time, we learned Drupal (and by extent PHP), caching strategies with Varnish, database management, and web security.
We created a place where users could blog, access FAQs, and organise social events to take the friendships that we'd all been making online into the offline space. This community grew and grew with an eventual total of over 6000 users.
This evolved over time to be tightly integrated with the chat server in such a way that users could manage their identity and metadata in one place with that information disseminated to all services; mainly through a combination of glue code, bash scripts, and cron jobs.
Due also to the scattering of students (and former students) who had moved into residences off campus but still wanted to stay connected, along with the rise in prevalence of mobile phones, we were pressed to build a solution that would allow anyone, anywhere to chat together.
Thus another bot (WebRelayBot) was born. The quick and hacky way proved to be robust and reliable with the bot spawning a child that watched for chat to be entered online and injecting it both into chat and into the database.
Looking back at the code from that time that I've got backed up, it seems we spent a lot of time understanding the pitfalls of parent and child processes; specifically because we needed to run it in a continuous while loop to listen for new chat messages.
The code snippet below from 2010 shows how we worked out how to spawn a child that would operate independently of the standard processes rather than acting upon the provided (and infrequent) server triggers. For a long time, the bot would become unresponsive very quickly after instantiation and it was only with the use of tools like Valgrind and Data::Dumper that we worked out it was becoming a zombie and needed some special love to not be reaped.
## VERY IMPORTANT: MUST HAVE $SIG{CHLD} SET TO IGNORE
## if it isn't then the bot will keep making forks and trying to keep
## up with the zombie processes. By not reaping the children it ignores
## them and they don't become zombies.
$SIG{CHLD} = 'IGNORE';
sub main()
{
&child();
}
sub child() {
## We need this or odch thinks the script is dead.
$pid=fork();
if($pid == 0) {
## Consider using a trigger such as Inotify2 instead of while.
while(1) {
open(LOGFILE) or die("Could not open log file.");
## In case the server dies and there is an accumulation of lines written from the web they'll all get pasted into chat when it lives again.
foreach $line (<LOGFILE>) {
chomp($line);
&log_and_send_data($line);
}
close LOGFILE;
&empty();
select(undef, undef, undef, 0.01);
}
}
pid_log();
}Not being content with polling on the website every few seconds for updates, we started to learn this new thing called Node.js which promised near instantaneous updates online.
Whilst none of us knew JavaScript, this really only needed the most moderate of code to be written. So we spent some more evenings testing a lot of different permutations, until finally it worked as we wanted. Using tools like Wireshark, netcat and nmap to make sure our sockets were working and data was being passed back and forth correctly was probably over the top for the goal. The knowledge it bestowed me with however, likely acted as a contributory catalyst for later on when I was doing this for real.
Over the next few months, we drank lots of coffee, stayed up late, scoured the internet for examples, and gained a ton of experience in everything that we needed to build the platform that we dreamed of and that all our user's wanted.
We ended up with a beautiful plate of spaghetti. Our systems and tools were "integrated" together, albeit with files, periodic rsyncs, and some Blu Tack. We had a backup-ish strategy, and an RTO of a couple of days, but more importantly it was something we'd built from scratch, and it worked really, really well.
During our time hacking scripts into code, code into modules, and modules into packages, I genuinely believe I learned more than I did during my actual university course – the one I was meant to be spending my time on.
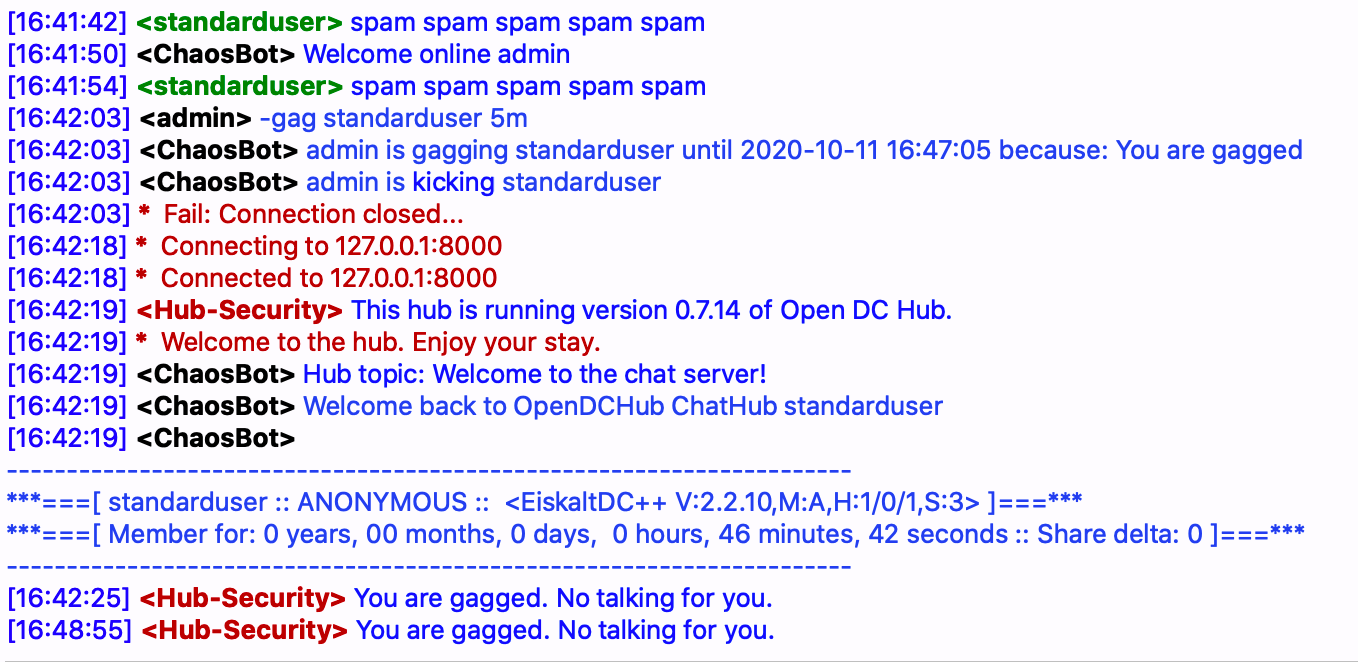
The last challenge related to usability was to introduce a function to temporarily gag unruly users. While we had functions to kick and ban users, sometimes a better solution was simply to prevent them from speaking for a few minutes. Unfortunately, this wasn't something that we could do with a bot as by the time it received triggers, user messages had already been sent out to all those subscribed to the channel.
This meant we had to learn C in order to alter the functionality of OpenDCHub itself. Taking lots of cues from how the ban function worked, we copied and pasted as needed to create a gaglist and allow authorised users to manage it. Our next step was to recompile the software and deploy it with our patch.
Otherwise harmless users who felt the need to spam were henceforth taken care of by allowing them to view chat, send PMs, and make use of bot commands; however they were temporarily prevented from speaking in main chat and annoying other users.
While everything inside the chat server was working well, university IT made changes that caused connections to our external server to be blocked. We weren't sure if this was on purpose or a consequence of other actions, but it gave us another challenge to get round in order to continue the service.
It didn't look like an IP block, as SSH connections were unhindered and we could still access the website. This led us to believe it was more likely to be either port blocking or packet sniffing. From here, we started learning encryption and SSL tunnelling as research indicated this to be a possible method of preventing our packets being sniffed.
Getting thousands of individual users to learn how to tunnel was likely not going to be a successful endeavour, especially since it took us a long time to learn how to do it ourselves. What we eventually landed on as a workable solution was Stunnel. A program that we could both install on the server and provide as a preconfigured package for users to install so it would work out of the box.
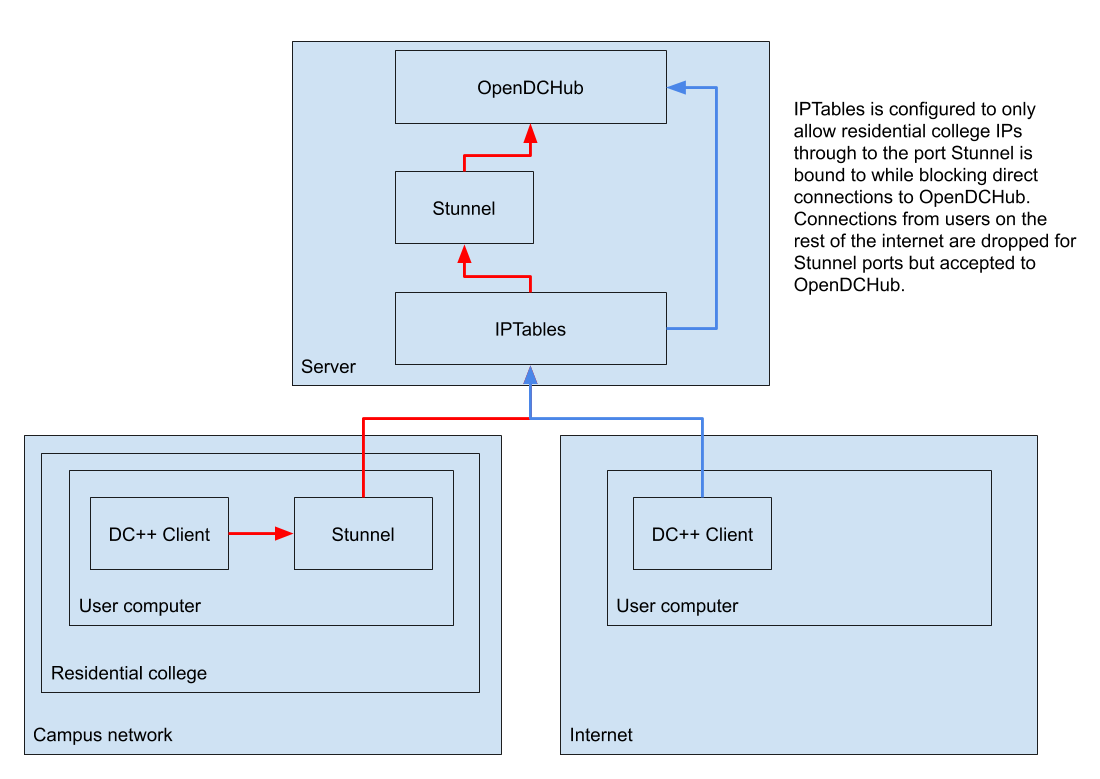
The network diagram above from our internal documentation and shows how we effectively blocked direct access to campus, requiring all residential college IP ranges to use Stunnel. The problem with Stunnel is that it identified all users as coming from localhost (127.0.0.1), since that's where users were proxying through. We wanted the ability to identify external users so required they connect directly through a different port. Learning IPTables made this possible since we could block ports based on where users were coming from.
Our next challenge was learning how to package preconfigured clients for Windows, Mac, and Linux so users wouldn't need to spend time and effort learning to configure a client and Stunnel by themselves. Our hypothesis was that by making everything install and connect with one click, we'd be more accessible to less technical users.
So with that, we set about packaging software and configuration into portable packages that could update with each new release of the underlying software – or if we needed to switch DNS/port due to the continual attempts at keeping the service running in the face of potential shut-down. The installers (and uninstallers) that we wrote married the advertised functionality with our trademark levity. The Mac installer for example starts talking to the user as it progresses through its assigned tasks.
This did eventually save our bacon when our shoestring budget operation forgot to update the free domain name we were using. The DynDNS service required us to log in once a month and click a button to keep the domain assigned to our IP or it would be placed back into their pool. Unfortunately, the specific tld that we used was moved onto the paid plan, so our domain was lost forever. Quickly rolling out new preconfigured software meant users were switched to a new domain with effectively no downtime.
The whole operation cost no money and earned us no money, but what it did provide us with was a phenomenal experience to meet new people, the ability to learn a lot of interesting code/technology, and the satisfaction of running a service that was firmly in the greyest of areas.
As a final hurrah to say goodbye to the university and to claim our victory in the cat and mouse game against the university IT department, the admin team went on an audacious outing to their office where we had our photo taken with out team hoodies on.

The choice
After completing my studies in the UK, I returned to Australia and began to hunt for a place of employment. I had a background and degree in chemistry, but a simultaneous passion for technology that had grown organically (when I was supposed to be studying) through the creation and management of this service with friends.
Prior to returning to Australia, I had submitted about 15-20 applications for graduate jobs within my field. Unfortunately, I received mostly the same boiler-plate responses from each organisation, which led me to believe that the working holiday visa I was on at the time was not sufficient for them to employ me.
I sought out other roles in my area and decided on a whim to apply for a developer role at a place that hadn't really said they were hiring. This entailed me walking into their office, CV and basic GitHub portfolio in hand, with an Oliver-esque request to be employed – something I'd assumed would never work.
The other role that I interviewed for was as a QA chemist at a pharmaceutical company. Make the chemicals over and over again and test them to make sure they're still the same.
It was at this point, with two offers in hand, that I made the decision on which direction my career should go. Do I do the thing that I've been spending the last four years studying for, or do I do the thing that I find fun?
I think it's obvious which path I took.




